隨著公司供水范圍的不斷擴大,供水規模不斷的提升,集中到調度中心的數據也越來越多。涵蓋生產調度、管網壓力監控、二次供水等。目前,我們使用的調度系統和管網壓力系統在監控運行和處理異常的時候主要存在以下問題:
1. 非自動:
現有的調度系統屬于“分析型”調度模式,對人員的主動性和能力的依賴性大。主要是對數據進行分析,然后進行經驗調度。
2. 信息的無序性。
在異常狀況下,調度員看到的是數據異常,要憑個人經驗判斷異常原因,然后進行驗證,得到驗證后,再通知相關部門進行處理,這個過程需要較長的時間。
3. 集中式控制方法缺乏。
由于存在多個系統,缺乏統一的平臺,不利于把控全局。隨著GIS平臺的建設,這一狀況將得到改善。
設想中的智能調度輔助決策系統能隨時跟蹤生產、管網的運行狀態,對異常情況能立即報警,并給出一個或幾個處理方案。該系統提供給調度人員在日常調度操作輔助決策參考,可使生產調度由目前的“人工分析型”調度上升為“計算機輔助智能型”。
從信息流的角度說,輔助決策系統應該涵蓋整個信息處理的過程。從初始的網絡分析的生成和驗證,到采用調度數據集成技術,有效整合并綜合利用生產、管網的運行信息,再經過數據過濾,獲取一個可靠的數據鏈,以此為基礎實現系統正常運行時的監測,并能對異常情況進行智能辨識,分析、給出決策方案。如下圖:
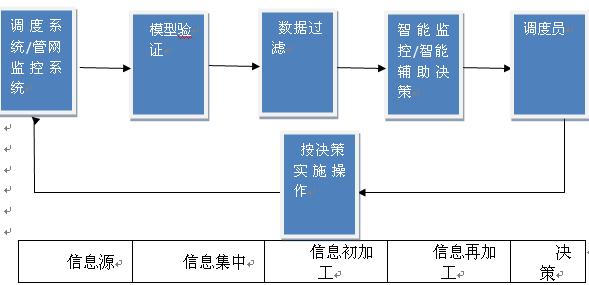
實現這一設想,可以分以下幾個階段:
1. 信息源的建立
目前,我們已經擁有了足夠多的信息源,已經有了各個系統,數據也已經集中了調度中心。
2. 模型的建立。
由于各個系統的數據量比較大,如何挑選其中的關鍵數據,作為模型的參數,就顯得尤為重要。例如,管網壓力監控系統,包含了上百個壓力監控點。在不同時段的的正常壓力值是不同的,還要考慮管徑的問題。那么就要挑選那些大管徑、主管網、重點區域的壓力控制點,作為一級控制點,然后是二級控制點。然后設定限值,建立關聯數據組。這種分級監控更容易對異常情況的嚴重性進行評估。
3. 數據采集
模型建好后,對接系統數據庫,實時獲取相關數據。
4. 模型驗證
在有實時數據的模型中,驗證模型的有效性,包括對異常數據的報警功能。關聯數據組的相關性時是否正確等。
5. 決策方案庫的建立與驗證
按照以往的實踐與經驗,建立決策方案庫,針對不同的報警類型,由系統生成決策方案。并由人工進行驗證,對不符合的方案進行優化,最終形成一個科學有效的方案生成體系。
智能調度輔助決策系統只是智慧化水務的一小步,它是一個半人工半自動化的系統,最終,我們還將實現智能決策與控制系統,由計算機來進行決策與控制,完全實現智能化。當然,這一切都離不開人的智慧在里面,實現智能化,不盲目依賴智能,不斷優化智能,是持續發展的根本。
(調度中心 邱石磊)